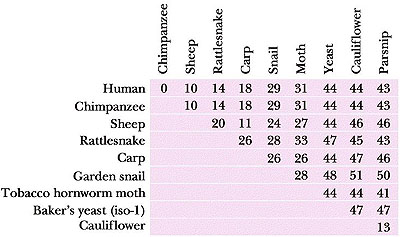
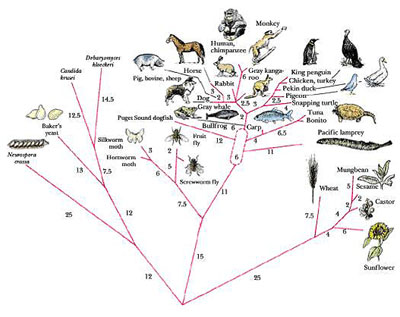
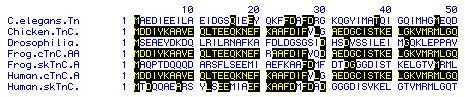
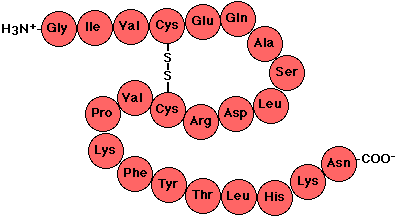
 La
estructura primaria viene determinada por la secuencia de AA en
la cadena proteica, es decir, el número de AA presentes y el orden
en que están enlazados (Figura de la derecha). Las posibilidades de estructuración
a nivel primario son prácticamente ilimitadas. Como en casi todas las
proteínas existen 20 AA diferentes, el número de estructuras posibles
viene dado por las variaciones con repetición de 20 elementos tomados
de n en n, siendo n el número de AA que componen la molécula proteica.
La
estructura primaria viene determinada por la secuencia de AA en
la cadena proteica, es decir, el número de AA presentes y el orden
en que están enlazados (Figura de la derecha). Las posibilidades de estructuración
a nivel primario son prácticamente ilimitadas. Como en casi todas las
proteínas existen 20 AA diferentes, el número de estructuras posibles
viene dado por las variaciones con repetición de 20 elementos tomados
de n en n, siendo n el número de AA que componen la molécula proteica.
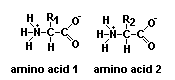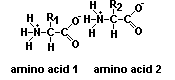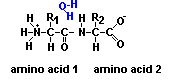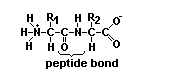 Generalmente, el número de AA que forman una proteína oscila
entre 80 y 300. Los enlaces que participan en la estructura primaria de
una proteína son covalentes: son los enlaces peptídicos. El enlace
peptídico (Figura de la izquierda) es un enlace amida que se forma
entre el grupo carboxilo de una AA con el grupo amino de otro, con eliminación
de una molécula de agua. Independientemente de la longitud de la cadena
polipeptídica, siempre hay un extremo amino terminal y un extremo carboxilo
terminal que permanecen intactos. Por convención, la secuencia de una
proteína se lee siempre a partir de su extremo amino (Figura superior).
Generalmente, el número de AA que forman una proteína oscila
entre 80 y 300. Los enlaces que participan en la estructura primaria de
una proteína son covalentes: son los enlaces peptídicos. El enlace
peptídico (Figura de la izquierda) es un enlace amida que se forma
entre el grupo carboxilo de una AA con el grupo amino de otro, con eliminación
de una molécula de agua. Independientemente de la longitud de la cadena
polipeptídica, siempre hay un extremo amino terminal y un extremo carboxilo
terminal que permanecen intactos. Por convención, la secuencia de una
proteína se lee siempre a partir de su extremo amino (Figura superior).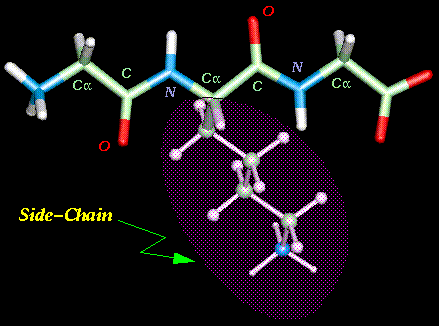 Como
consecuencia del establecimiento de enlaces peptídicos entre los distintos
AA que forman la proteína se origina una cadena principal o "esqueleto"
a partir del cual emergen las cadenas laterales de los AA (Átomos
sombreados en la Figura de la derecha).Los átomos
que componen la cadena principal de la proteína son el N del grupo amino
(condensado con el AA precedente), el Ca
(a partir del cual emerge la cadena lateral) y el C del grupo carboxilo
(que se condensa con el AA siguiente). Por lo tanto, la unidad repetitiva
básica que aparece en la cadena principal de una proteína es: (-NH-Ca-CO-)
Como
consecuencia del establecimiento de enlaces peptídicos entre los distintos
AA que forman la proteína se origina una cadena principal o "esqueleto"
a partir del cual emergen las cadenas laterales de los AA (Átomos
sombreados en la Figura de la derecha).Los átomos
que componen la cadena principal de la proteína son el N del grupo amino
(condensado con el AA precedente), el Ca
(a partir del cual emerge la cadena lateral) y el C del grupo carboxilo
(que se condensa con el AA siguiente). Por lo tanto, la unidad repetitiva
básica que aparece en la cadena principal de una proteína es: (-NH-Ca-CO-)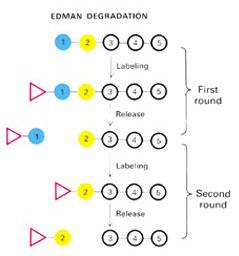 Como
la estructura primaria es la que determina los niveles superiores de organización,
el conocimiento de la secuencia de AA es del mayor interés para el estudio
de la estructura y función de una proteína. Clásicamente, la secuenciación
de una proteína se realiza mediante métodos químicos. El método
más utilizado es el de Edman, que utiliza el fenilisotiocianato
para marcar la proteína (representado en la Figura de la izquierda
como un triángulo) e iniciar una serie de reacciones cíclicas
que permiten identificar cada AA de la secuencia empezando por el extremo
amino. Hoy en día esta serie de reacciones las realiza de forma
automática un aparato llamado secuenciador de AA.
Como
la estructura primaria es la que determina los niveles superiores de organización,
el conocimiento de la secuencia de AA es del mayor interés para el estudio
de la estructura y función de una proteína. Clásicamente, la secuenciación
de una proteína se realiza mediante métodos químicos. El método
más utilizado es el de Edman, que utiliza el fenilisotiocianato
para marcar la proteína (representado en la Figura de la izquierda
como un triángulo) e iniciar una serie de reacciones cíclicas
que permiten identificar cada AA de la secuencia empezando por el extremo
amino. Hoy en día esta serie de reacciones las realiza de forma
automática un aparato llamado secuenciador de AA.