ABC domain: dominio ABC.
![]() ATP-binding
domain.
ATP-binding
domain.
ABC protein: proteína
de la familia ABC.
Cualquiera de los miembros de la mayor familia conocida de proteínas
que transportan sustancias a través de una membrana celular. La
sigla «ABC», que da nombre a la familia –o a la «superfamilia»,
como algunos gustan llamarla debido a la gran cantidad de miembros que
la componen–, es la abreviatura de ATP-binding cassette,
uno de los dos dominios de unión a ATP localizados en el citoplasma
celular que, junto con otros dos dominios transmembranarios que proporcionan
la especificidad por el sustrato, son característicos de estas
proteínas.
Observación: las sustancias transportadas a través
de la membrana celular son muy diversas (p.ej., metabolitos, lípidos,
esteroles y fármacos), y el transporte se hace generalmente en
una sola dirección y con gasto de energía mediante hidrólisis
de ATP. En los organismos eucariotas, estos transportadores por lo general
movilizan compuestos desde el citoplasma hacia el exterior de la célula
o hacia el interior de un orgánulo (mitocondria, retículo
endoplasmático, peroxisomas, etc.). Por el contrario, en las bacterias,
estas proteínas participan sobre todo en la importación
de compuestos esenciales que no pueden ingresar en la célula por
mecanismos de difusión (p.ej., hidratos de carbono, vitaminas,
iones metálicos, etc.). Por lo menos seis miembros de la familia
se asocian a transporte de fármacos y están implicados
en mecanismos de multirresistencia farmacológica en enfermedades
como el cáncer. No todas las proteínas ABC desempeñan
una función de transporte. Por ejemplo, la enzima de reparación
del ADN, UvrA, es una proteína ABC sin función transportadora.
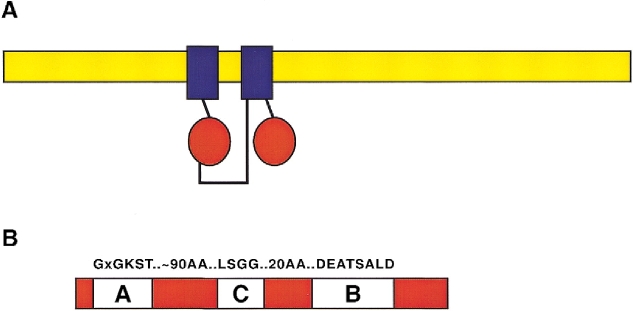 |
| Diagrama de un transportador ABC típico. A) Estructura esquemática de la proteína (cuadrados y círculos en azul y rojo) dentro de la membrana plasmática (en amarillo), con dos dominios transmembranarios (en azul) y dos dominios citoplasmáticos de unión a ATP (en rojo). B) Cada dominio de unión a ATP de la proteína ABC contiene dos motivos breves, que también están presentes en otras proteínas con dominios de unión a nucleótidos, denominados Walker A y Walker B, más un tercer dominio C distintivo (signature) de la familia. Fuente: http: //www.genome.org/content/vol11/issue7/images/large/19f1_C4TT.jpeg |
ABC superfamily: superfamilia
de proteínas ABC.
![]() ABC
protein.
ABC
protein.
aberrant mRNA : ARNm aberrante.
Moléculas de ARNm de características peculiares (ARN ultraleídos —readthrough—,
con estructura secundaria compleja debido a la presencia de apareamientos
intracatenarios, con modificaciones covalentes, con falta de edición
o ARN incompletos), que son sustrato de degradación por parte
de proteínas específicas en la ribointerferencia. Véase readthrough, RNA
editing y RNA interference.
abzyme: aczima.
Anticuerpo con actividad catalítica (por ejemplo, actividad de
ribonucleasa).
Observación: el término abzyme —por antibody
enzyme— se debería verter al español respetando
la abreviatura española de anticuerpo y no la inglesa; es decir,
la ab de antibody debería convertirse en la ac de anticuerpo.
acceptor site : sitio aceptor.
![]() splice
site.
splice
site.
acceptor splice site : sitio
aceptor.
![]() splice
site.
splice
site.
activator: activador.
1. Biol. Mol. Proteína con función reguladora
que aumenta la frecuencia de transcripción de un gen. Por lo
general se trata de un factor de transcripción que reconoce
y se une a una secuencia nucleotídica breve cerca del promotor
del gen que regula, al promotor mismo o a un potenciador de la transcripción.
2. Enzimol. Compuesto que aumenta la velocidad de la
reacción enzimática, distinto de un catalizador o de
su sustrato.
Observación: en los organismos procariotas, un
activador (acepción 1.ª) posee dos dominios separados característicos,
el primero es un dominio de unión a una región específica
del ADN situada generalmente cerca del promotor del gen y el segundo es
un dominio de interacción con la ARN-polimerasa. En estos casos,
la activación se realiza 1) al facilitar la unión de la polimerasa
al promotor (el activador se une por un dominio al ADN y por el otro a
la ARN-polimerasa, como en el caso del operón lac; la activación
en estos casos ocurre incluso en presencia de un represor transcripcional),
o bien 2) al interaccionar con el complejo cerrado (es decir, con la ARN-polimerasa
ya unida a la doble hélice ADN) de modo que se produce un cambio
conformacional en la ARN-polimerasa o el ADN, el complejo cerrado pasa
al estado abierto y se inicia la transcripción. Un activador también
puede ejercer su efecto a distancia. En estos casos, el activador (p.ej.,
NtrC) se une a segmentos de ADN que pueden estar situados a unos pocos
cientos de pares de bases del promotor (en dirección 5’), y
la interacción con la ARN-polimerasa sólo es posible si el
ADN se pliega y los sitios de unión del activador al ADN y de la
ARN-polimerasa al ADN quedan próximos entre sí.
En los organismos eucariotas, los activadores también poseen
dos dominios separados, pero rara vez interactúan con la ARN-polimerasa
de forma directa. Más bien promueven la unión de la ARN-polimerasa
al ADN (y la formación de complejos de iniación) de forma
indirecta por dos vías distintas: 1) el activador interacciona únicamente
con proteínas o complejos proteicos que forman parte del aparato
transcripcional, distintos de la ARN-polimerasa (p.ej.: un coactivador
o el factor de transcripción TFIID), y éstos a su
vez se unen a la ARN-polimerasa que se fija al ADN para formar el complejo
de iniciación transcripcional correspondiente en el promotor;
2) el activador atrae modificadores de los nucleosomas (p.ej.: histona-acetilasas
o factores de remodelado de la cromatina) que producen un cambio conformacional
en la región de la cromatina cercana al gen en cuestión
para que la ARN-polimerasa pueda unirse al ADN y formar el complejo de
iniciación transcripcional correspondiente. El activador que es
capaz de interaccionar de forma directa con la polimerasa, sin el auxilio
de coactivadores, recibe el nombre de «transactivador».
active center: sitio activo.
![]() active site
active site
active site: sitio activo.
Región de la enzima (usualmente un hueco, una cavidad o una hendidura
de carácter no polar) a la que se une al sustrato y donde tiene
lugar la reacción biológica, pues contiene los aminoácidos
que participan de forma directa en la formación o ruptura de enlaces.
Observación:
también se conoce como centro activo
(active center) o centro catalítico (catalytic site).
No obstante, existen autores que distinguen el sitio activo o sitio catalítico
propiamente dicho (el lugar donde tiene lugar la reacción enzimática)
del sitio de unión de la enzima con el sustrato en los casos en
que ambas regiones se superponen sólo parcialmente.
acyl- : acil-.
Nombre genérico del grupo funcional que resulta de la eliminación
de un grupo hidroxilo de los ácidos orgánicos tales como
los aminoácidos.
acylated tRNA : aminoacil-ARNt.
![]() aminoacyl tRNA.
aminoacyl tRNA.
AFLP: AFLP.
![]() amplified
fragment-length polymorphism.
amplified
fragment-length polymorphism.
AFLP fingerprints: polimorfismo
de la longitud de fragmentos amplificados.
![]() amplified
fragment-length polymorphism.
amplified
fragment-length polymorphism.
allele : alelo.
Cada una de las posibles formas en las que existe un gen a consecuencia
de una o más mutaciones.
Observación: la palabra allele se ha formado por
apócope y cambio de la vocal «o» por «e» a
partir de la voz allelomorph, que William Bateson había
acuñado a comienzos del siglo xx (y que significa literalmente «forma
alternativa»). Los alelos (o genes alélicos) están
situados en loci idénticos en cromosomas homólogos. Véase
homologous chromosome y locus.
allelomorph : alelomorfo.
![]() allele.
allele.
alternative splicing : corte
y empalme alternativo, ayuste alternativo.
Proceso de obtención de ARNm distintos a partir de un mismo transcrito
primario por alternancia de las posibilidades de corte y empalme (ayuste)
intrónico. De resultas de este proceso, cada uno de los ARNm obtenidos
contiene distintos exones del gen a partir del cual ha sido transcrito.
Véase exon y splicing.
amino acid-accepting RNA : ARN
de transferencia.
![]() transfer
RNA.
transfer
RNA.
amino acid-tRNA ligase : aminoácido-ARNt-ligasa.
Grupo de enzimas específicas que catalizan la formación
de un aminoacil-ARNt (L-aa- ARNtaa) a
partir de ATP, el aminoácido específico (L-aa) y el ARNt
aceptor correspondiente (ARNtaa), con liberación
de pirofosfato (PPi) y AMP:
ATP + L-aa + ARNtaa = AMP + PPi +
L-aa- ARNtaa
Hay tantas aminoácido-ARNt-ligasas como aminoácidos constituyentes
de proteínas (21): tirosina-ARNt-ligasa, leucina-ARNt-ligasa, ß-alanina-ARNt-ligasa,
etc.
Observación: según el Comité de Nomenclatura
de la Unión Internacional de Bioquímica y Biología
Molecular (NC-IUBMB), el nombre oficial de estas enzimas del grupo
6.1.1 (Ligases forming aminoacyl-tRNA and related compounds) es aminoacid-ARNt
ligases, pero también reciben otras denominaciones: aminoacyl-tRNA
synthetases; aminoacyltransfer ribonucleate synthetases; aminoacyl-transfer
RNA synthetases; aminoacyl-transfer ribonucleic acid synthetases; aminoacyl-tRNA
ligases; amino acid-transfer RNA ligases; amino acid-transfer ribonucleate
synthetases; amino acid translases; amino acid tRNA synthetases.
aminoacyl tRNA : aminoacil-ARNt.
Molécula de ARNt unida a su aminoácido específico.
La unión se efectúa mediante un enlace éster entre
el carboxilo del aminoácido y el hidroxilo de la posición
3’ de la adenosina terminal del ARNt. Las enzimas que catalizan
estas uniones son las aminoácido-ARNt-ligasas.
aminoacyl-tRNA synthetase : aminoácido-ARNt-ligasa.
![]() aminoacid-tRNA
ligase.
aminoacid-tRNA
ligase.
amplicon: amplicón.
Conjunto de moléculas de ADN idénticas que resulta de una
reacción en cadena de la polimerasa (PCR). Es esencialmente un
clon molecular. Véase clone y PCR.
amplified fragment-length polymorphism: polimorfismo
de la longitud de fragmentos amplificados.
 Es una
variante de la técnica de la huella genética (DNA
fingerprinting) que se basa en la amplificación selectiva,
mediante una reacción en cadena de la polimerasa (PCR), de fragmentos
procedentes de la digestión de un ADN genómico con un
par de enzimas de restricción. Véase DNA fingerprinting.
Es una
variante de la técnica de la huella genética (DNA
fingerprinting) que se basa en la amplificación selectiva,
mediante una reacción en cadena de la polimerasa (PCR), de fragmentos
procedentes de la digestión de un ADN genómico con un
par de enzimas de restricción. Véase DNA fingerprinting.
Observación: el método original de Pieter Vos
y cols. consta de tres etapas: 1) la digestión del ADN con un
par de enzimas de restricción (p. ej.: EcoRI y MseI)
y el ligamiento de oligodesoxinucleótidos bicatenarios (adaptadores)
a los extremos de los fragmentos producidos; 2) la amplificación
selectiva de un conjunto de esos fragmentos mediante un par de cebadores
complementarios de los adaptadores y de las secuencias de reconocimiento
de las enzimas de restricción (un cebador para los extremos
escindidos con EcoRI y el segundo cebador para los extremos
escindidos con MseI; véase el esquema). Los cebadores
disponen de tres nucleótidos sobrantes en su extremo 3’ (los
nucleótidos «selectivos», véase el esquema),
que sólo reconocerán (y permitirán amplificar)
los fragmentos de restricción que tengan los correspondientes
tres nucleótidos complementarios flanqueando el sitio de restricción,
reduciendo de forma considerable (1/16 por cada nucleótido selectivo)
el número de fragmentos que se amplifican; 3) el análisis
de los fragmentos amplificados en un gel de electroforesis. Este método
puede generar una huella genética a partir de cualquier muestra
de ADN, sin importar su origen ni complejidad, sin conocimiento previo
de secuencia alguna y sin los inconvenientes de otros métodos
de tipificación que son extremadamente sensibles a las condiciones
de reacción, a la calidad del ADN y a las variaciones de temperatura.
Permite, además, la amplificación simultánea de
un gran número de fragmentos de restricción (generalmente
de 50 a 100) en cada análisis realizado.
amino acid: aminoácido.
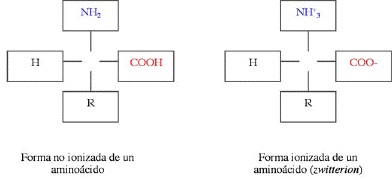 Unidad
estructural de una proteína. Es un ácido orgánico
compuesto de un grupo amino (-NH2),
un grupo carboxilo (-COOH), un átomo
de hidrógeno (-H) y un grupo distintivo o radical (-R) unidos
a un átomo de carbono central (denominado «carbono alfa» por
ser adyacente al grupo carboxilo; no marcado en la figura). En un medio
acuoso de pH neutro, los aminoácidos individuales existen predominantemente
como iones bipolares o dipolos (zwitteriones):
Unidad
estructural de una proteína. Es un ácido orgánico
compuesto de un grupo amino (-NH2),
un grupo carboxilo (-COOH), un átomo
de hidrógeno (-H) y un grupo distintivo o radical (-R) unidos
a un átomo de carbono central (denominado «carbono alfa» por
ser adyacente al grupo carboxilo; no marcado en la figura). En un medio
acuoso de pH neutro, los aminoácidos individuales existen predominantemente
como iones bipolares o dipolos (zwitteriones):
Observación: por
aminoácido debe entenderse casi siempre un ácido orgánico
que lleva el grupo amino en el carbono 2 (α) de la cadena hidrocarbonada,
y menos frecuentemente en el carbono 3 (ß). El hecho de que el
carbono a esté rodeado de cuatro grupos diferentes le confiere
actividad óptica a cada aminoácido, que entonces puede
existir en dos formas especulares (isómeros) distintas: la forma
levógira (L) y la forma dextrógira (D). Los aminoácidos
naturales son todos levógiros. Se conocen en la actualidad 20
radicales (-R) distintos, de naturaleza tanto alifática como
aromática, que dan lugar a los 20 aminoácidos naturales
conocidos. Estos aminoácidos se representan con un símbolo
universal de una o tres letras, a saber: alanina (A, Ala), arginina
(R, Arg), asparragina (N, Asn), ácido aspártico (D, Asp),
cisteína (C, Cys), glutamina (Q, Gln), ácido glutámico
(E, Glu), glicocola o glicina (G, Gly), histidina (H, His), isoleucina
(I, Ile), leucina (L, Leu), lisina (K, Lys), metionina (M, Met), fenilalanina
(F, Phe), prolina (P, Pro), serina (S, Ser), treonina (T, Thr), triptófano
(W, Trp), tirosina (Y, Tyr) y valina (V, Val). La asparragina y la
glutamina son los derivados sin carga neta (las formas bipolares iónicas
o zwitteriones) de los ácidos aspártico y glutámico,
respectivamente, cuyos radicales (-R) son de naturaleza ácida
a pH biológico. Cuando en una secuenciación no se distingue
un compuesto del otro, se utiliza la nomenclatura «B, Asx» para
la asparragina o el ácido aspártico, y «Z, Glx» para
la glutamina o el ácido glutámico. Existen dos aminoácidos
adicionales que se pueden incorporar de manera natural a las proteínas
durante su síntesis: la selenocisteína (muy distribuida
en la naturaleza y presente en algunas enzimas como la glutatión-peroxidasa
y la formato-deshidrogenasa) y la pirrolisina (presente en las bacterias
del género Methanosarcina, del dominio Archaea).
Los aminoácidos 21 y 22 no tienen un codón propio y se
insertan en las proteínas en el lugar de ciertos codones de
finalización. Véase building
block.
amino acid residue: residuo
de aminoácido.
Aminoácido incorporado a un péptido o a una proteína.
Observación: la reacción de condensación que
ocurre entre el grupo carboxilo de un aminoácido y el grupo amino
de otro cuando ambos se unen a través de un enlace peptídico
suele acompañarse de la pérdida de una molécula
de agua (formada a partir del átomo de hidrógeno de uno
y el grupo hidroxilo del otro). Debido precisamente a esa pérdida
de un átomo de hidrógeno o un grupo hidroxilo se habla
entonces de «residuos» de aminoácidos. Dicho esto,
cabe destacar que, en la práctica, suele hablarse de los aminoácidos (y
no de los residuos de aminoácidos) de una proteína,
excepto cuando se hace referencia a la secuencia de un polipéptido
obtenida por la degradación de Edman.
annealing: hibridación,
apareamiento.
Unión de dos hebras de ácido nucleico por complementariedad
de bases; por ejemplo, el apareamiento de dos hebras de ADN para formar
una doble hélice
annotation: anotación.
Descripción de la localización precisa, el tamaño y la
función (o las funciones) de las secuencias de nucleótidos (genes,
regiones reguladoras y otros elementos) de un genoma (ADN o ARN) o de las secuencias
de aminoácidos de una proteína, y asignación de una función
biológica probable a dichas secuencias por comparación con otras
secuencias homólogas descritas en los bancos de datos. Esta tarea supone,
además, un trabajo de edición informática —que algunos
distinguen de la annotation propiamente dicha con el nombre de
curation—, así como la inclusión de cualquier otra
información pertinente sobre la secuencia descrita. Véase CURATION.
antibody: anticuerpo.
Glucoproteína plasmática producida por un linfocito B al entrar
en contacto con un antígeno específico. Recibe también el
nombre de inmunoglobulina. Se trata de la forma soluble del receptor de antígeno
presente en la membrana plasmática del linfocito B, cuya síntesis
se induce tras el reconocimiento específico del ligando (el antígeno).
Todos los anticuerpos presentan la misma estructura básica (véase
la figura), pero la región de unión con el antígeno, conocida
como parátopo, es extremadamente variable y característica de cada
uno de ellos.
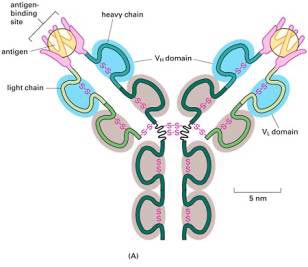 |
Figura: Estructura básica de un anticuerpo Una molécula de anticuerpo está formada por cuatro polipép-tidos; dos polipéptidos idénticos de tamaño mayor (cadenas polipeptídicas pesadas o heavy chains, en verde oscuro) y dos polipéptidos idénticos de tamaño menor (cadenas polipeptídicas livianas o light chains, en verde claro), unidas por puentes disulfuro (s-s) y otros enlaces covalentes y no covalentes. El contacto con el epítopo del antígeno (señalado con un círculo) se establece en un punto de unión específico: el parátopo o antigen binding site (señalado en color fucsia) ubicado en la región variable de cada anticuerpo (sombreada en color celeste), formada por los extremos N de las cadenas pesadas y ligeras (VH, VL). Existen dos regiones variables y dos parátopos por molécula de anticuerpo. El resto de la molécula presenta una estructura constante, común a todas las inmunoglobulinas (sombreada en color gris). El punto de bifurcación de la Y, donde existen dos puentes disulfuro, constituye la región de la bisagra (hinge). Tanto las cadenas livianas como las pesadas contienen una serie de unidades repetidas de unos 110 aminoácidos cada una que se pliegan de forma independiente y forman un motivo estructural globular denominado dominio Ig (regiones con forma de herradura). Figura extraída de http://privat.hihm.no/robertw/molbio/5BI37Web/LabExercise5b-filer/image004.jpg |
anticoding strand : cadena
no codificante.
![]() noncoding
strand.
noncoding
strand.
anticodon : anticodón.
Triplete de nucleótidos de un ARNt que se aparea con un codón
específico del ARNm por complementariedad de bases a través
de puentes de hidrógeno. El apareamiento es antiparalelo, de modo
que el extremo 5' de una secuencia coincide con el extremo 3’ de
la otra, por ejemplo:
5’-ACG-3’ (codón)
3’-UGC-5’ (anticodón).
No obstante, para mantener la convención de escritura de las secuencias
de nucleótidos en la dirección de 5’ a 3’ suele
escribirse el anticodón al revés, con una flecha en dirección
opuesta arriba.
antigen: antígeno.
1 Cualquier
sustancia que, al ingresar en un organismo inmunocompetente, estimula la producción de una o varias series de anticuerpos específicos
que se unen a ella a través de unos sitios denominados epítopos
o determinantes antigénicos. Un mismo antígeno puede contener múltiples
epítopos, algunos de los cuales pueden estar repetidos, y cada epítopo
es específico de un anticuerpo. En esta acepción, antígeno
es sinónimo de inmunógeno. Véase IMMUNOGEN.
2 Cualquier
sustancia que es capaz de unirse de forma específica
a un anticuerpo o a un receptor localizado en la superficie de los linfocitos
T. Los antígenos que se unen a anticuerpos son de naturaleza extremadamente
diversa (pueden ser desde sustancias relativamente sencillas, como los lípidos
y las hormonas, hasta macromoléculas más complejas, como los ácidos
nucleicos y las proteínas, e incluso virus o un fragmento de célula,
por citar unos ejemplos); en cambio, los que se unen con el receptor de superficie
de los linfocitos T son únicamente de naturaleza proteínica. En
esta acepción, antígeno no es necesariamente sinónimo de
inmunógeno. Véase, por ejemplo, la entrada HAPTEN.
Observación: el
término antigen proviene
de la contracción del inglés antibody generator (generador
de anticuerpos).
antigen binding site: parátopo.
→ PARATOPE
antigen mimicry: mimetismo antigénico.
Inmunol. Propiedad
de ciertos anticuerpos antiidiotípicos de
guardar semejanza estructural con el determinante antigénico reconocido
por el anticuerpo original (este es el anticuerpo que ha inducido la producción
de anticuerpos antiidiotípicos).
antigenic determinant: determinante
antigénico.
→ EPITOPE
antiidiotype antibodies: anticuerpos
antiidiotípicos.
Anticuerpos que reconocen específicamente los idiótopos de otro
anticuerpo. Véanse IDIOTOPE e IDIOTYPE.
antiport: cotransporte
bidireccional.
Traslado de dos solutos de un lado a otro de una membrana biológica
de forma simultánea y en direcciones opuestas. Véase cotransport.
Observación: en los libros de texto se traduce con frecuencia
por «antiporte», pero en esos casos casi siempre se especifica
que es un cotransporte bidireccional.
antiporter: antiportador.
Transportador de dos solutos en direcciones opuestas. Véase porter.
antisense RNA : ARN antisentido,
ARN complementario.
1 Molécula de ARN complementaria de una molécula
de ARN transcrito, que al formar híbridos con esta última
estorba el desempeño de su función; por ejemplo, si el
ARN transcrito es un ARNm, puede llegar a impedir su traducción
en proteína. En este último caso, también puede
traducirse por «ARN antimensajero».
2 Molécula de ARN sintetizada in vitro que servirá de
sonda en experimentos de hibridación molecular.
Observación: estos ARN pueden ser sintéticos o
naturales. Cuando son sintéticos se suelen llamar micRNA,
por messenger-RNA-interfering comple-mentary RNA o messenger
interfering complemen-tary RNA, y suelen ser complementarios del
extremo 5’ de un ARNm. Los naturales desempeñan, por lo
general, una función reguladora al disminuir la expresión
del ARNm correspondiente.
antisense-RNA control : regulación
por ARN complementario, regulación por ARN antiparalelo, regulación
por ARN antisentido.
1 Mecanismo de regulación génica común
a los tres reinos de la naturaleza, observado solo recientemente en
los organismos eucariotas. Los ARN monocatenarios reguladores se unen,
por complementariedad total o parcial de bases, a uno o varios ARN
monocatenarios efectores o mensajeros específicos (sense
RNA) y, tras formar el híbrido correspondiente, logran impedir
el desempeño de la función del ARN efector o la traducción
en proteína del ARN mensajero.
2 Por extensión, técnica de laboratorio
que se basa en la utilización de ARN monocatenarios complementarios
para reducir la expresión de un gen específico.
Observación: los ARN complementarios naturales suelen
ser moléculas de 35 a 150 nucleótidos de largo, de estructura
terciaria compleja (que facilita el reconocimiento y la unión
al ARN específico) y con capacidad de difundir a otros compartimentos
celulares. Pueden estar codificados en cis (es decir, se transcriben
de un promotor localizado en la hebra opuesta de la misma molécula
de ADN) o, más raramente, en trans. Desde el punto de vista
metabólico algunos son estables (la mayoría de los codificados
en cromosomas y unos cuantos de origen fágico o transposónico),
pero otros son inestables (los implicados en la regulación del
número de copias de plásmidos). Véase antisense
rna y sense rna.
antisense strand : cadena
no codificante.
![]() noncoding
strand.
noncoding
strand.
antitemplate strand : cadena
codificante.
![]() coding
strand.
coding
strand.
antizymes: antizimas.
Familia de proteínas pequeñas que se unen y desestabilizan
a la enzima ornitina-descarboxilasa (ODC). La antizima se induce en presencia
de poliaminas y se une a la ODC para formar heterodímeros que
carecen de actividad enzimática. No son «antienzimas».
AP-PCR: AP-PCR.
![]() arbitrarily
primed PCR.
arbitrarily
primed PCR.
apoenzyme: apoenzima.
Porción proteica inactiva de una enzima, que sólo adquiere
capacidad catalítica cuando se combina con el cofactor correspondiente
(ión metálico, grupo prostético, coenzima). La enzima íntegra
(la apoenzima unida al cofactor) se denomina «holoenzima» o «proteína
conjugada». La apoenzima es la que determina la especificidad de
la reacción biológica. Véase conjugated
protein.
aptamer: aptómero.
Ácido nucleico sintético de unos 70-80 nucleótidos
capaz de reconocer y unirse a una gran variedad de moléculas.
Observación: Los aptómeros fueron descubiertos
en 1990, y desde entonces han cobrado una gran importancia en el ámbito
de las técnicas diagnósticas por su capacidad de plegarse
y de reconocer y unirse a dianas muy variadas (desde proteínas
hasta iones metálicos, pasando por colorantes orgánicos,
aminoácidos y péptidos, cofactores, aminoglucósidos,
antibióticos y otros fármacos, análogos de base,
nucleótidos, etc.). Se unen con una afinidad y especificidad
semejantes a las que presentan los anticuerpos hacia sus antígenos,
de hecho, pueden discriminar ligandos sobre la base de diferencias
estructurales tan pequeñas como la presencia o la ausencia de
un grupo metilo o hidroxilo, e incluso los enantiómeros de una
misma sustancia. Son resistentes a endonucleasas o exonucleasas si
se fabrican con nucleótidos modificados o se recubren sus extremos
con ligandos específicos, y a ciclos consecutivos de desnaturalizaciones
y renaturalizaciones por acción del calor u otros factores,
característica poco frecuente en las proteínas, salvo
las de los organismos termófilos. Se pueden marcar con cromóforos
específicos (como la biotina o la fluoresceína). Hoy
día es posible reemplazar los conjugados anticuerpo-enzima utilizados
en el diagnóstico por conjugados aptómero-enzima, aunque
todavía se desconoce la naturaleza de la interacción
que tiene lugar entre estas moléculas y sus ligandos.
arbitrarily primed
PCR: PCR con cebado aleatorio.
Método sencillo y reproducible que permite obtener huellas de
genomas complejos (fingerprints) utilizando cebadores de secuencia
no especificada (sintetizados al azar) y la reacción en cadena
de la polimerasa (PCR). Comprende dos ciclos de amplificación
del ADN en condiciones poco rigurosas (low stringency) y luego
una reacción en cadena de la polimerasa en condiciones de mayor
rigurosidad (higher stringency).
Observación: en este caso específico, arbitrary no
significa «arbitrario» (irracional, injusto, caprichoso,
subjetivo), sino «aleatorio» o «azaroso» (en
su acepción de based on a chance) y se refiere a la elección
de los cebadores. De allí que, en la práctica, este método
(AP-PCR) se confunda con otro prácticamente idéntico, el
del ADN polimórfico amplificado al azar (RAPD). Véase DNA
fingerprinting y random amplified polymorphic
DNA.
Argonaute proteins : proteínas
Argonauta.
Familia de proteínas que se caracterizan por tener dos dominios
estructurales denominados PAZ y Piwi (este último en el extremo
carboxilo). Se identificaron inicialmente en mutantes de Arabidopsis que
presentaban una morfología foliar anómala, pero luego se
comprobó que existen en numerosos organismos eucariotas. Un miembro
de esta familia, la Ago-2, es una subunidad del complejo RISC
en Drosophila melanogaster.
aRNA : ARNa.
![]() antisense
RNA.
antisense
RNA.
ATP-binding cassette domain: casete
de unión a ATP, dominio de unión a ATP.
![]() ATP-binding
domain.
ATP-binding
domain.
Observación: se debe escribir ya sea «casete de
unión a ATP» o bien «dominio de unión a ATP»,
pero no «dominio de casete de unión a ATP» (recuérdese
que estos casetes son de por sí dominios proteicos), aunque no
es raro verlo escrito de forma abreviada «dominio ABC».
ATP-binding cassette: casete
de unión a ATP.
![]() ATP-binding
domain.
ATP-binding
domain.
ATP-binding domain: dominio
de unión a ATP.
Observación: recibe asimismo los nombres de nucleotide-binding
fold (NBF), ATP-binding cassette, ABC, y ATP-binding
cassette domain. Véase cassette y domain.
automated sequencing: secuenciación
automática.
Método de secuenciación de ADN basado en el método de
Sanger que se realiza en unos aparatos automatizados especiales denominados secuenciadores.
Se diferencia del método de Sanger sobre todo en que la marcación
no se realiza con radioisótopos, sino con fluoróforos, que en los
secuenciadores de segunda generación van unidos a los didesoxirribonucleótidos
(‘terminadores de cadena’). En las secuenciaciones de segunda generación,
pues, cada didesoxirribonucleótido lleva un fluoróforo distinto,
de modo que la elongación del cebador se puede hacer en una única
reacción (y no en cuatro reacciones paralelas como en el método
original de Sanger). Por consiguiente, las bandas de electroforesis tampoco se
revelan por autorradiografía como en el método de Sanger, sino
que los fluoróforos son excitados con rayos láser y un sensor situado
en la base del gel de electroforesis capta la fluorescencia que éstos
producen. La secuencia de nucleótidos es ‘leída’ de
forma automática por el aparato a medida que los fragmentos fluorescentes
de ADN que se van separando electroforéticamente con arreglo a su tamaño
específico desfilan delante del sensor. Cuando se trabaja con pequeñas
cantidades de ADN se puede llevar a cabo una reacción en cadena de la
polimerasa (PCR) en presencia de los fluoróforos específicos. En
la actualidad, es cada vez más frecuente la utilización de la electroforesis
en capilar, dado que ocupa menos espacio (se desarrolla en un capilar de 20 a
200 mm de diámetro), acepta cantidades y volúmenes muy pequeños
de la muestra (picomoles, nanolitros), es muy rápida (en tres horas pueden
leerse de 500 a 600 bandas) y tiene un gran poder de resolución. Véanse
SEQUENCER y CAPILLARY SEQUENCING.